Memory System
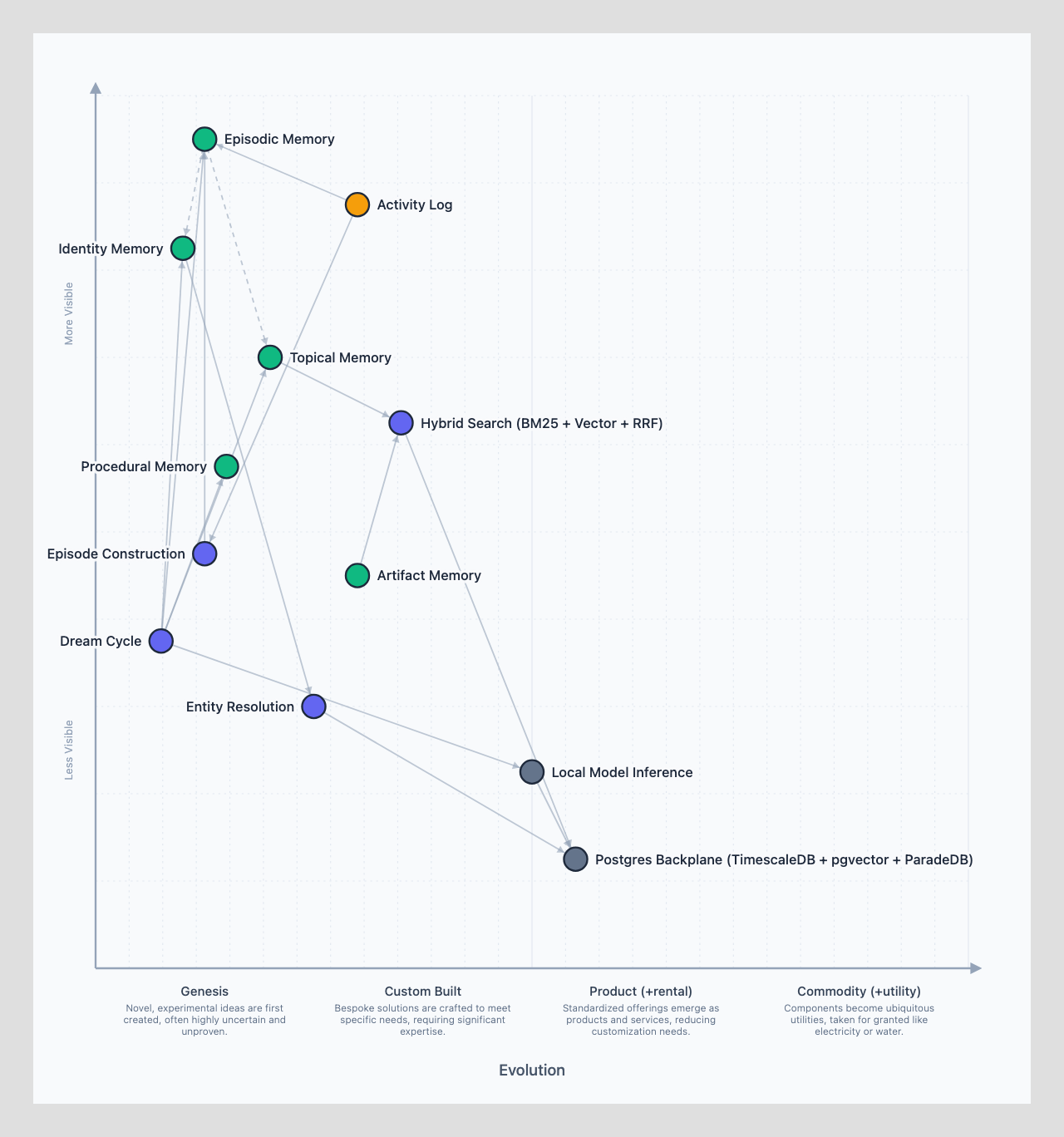
Your agent has amnesia -- every session starts from scratch. The memory system gives it continuity by organizing information into five layers built on an activity log foundation. Each layer serves a different recall pattern: what happened (episodic), who people are (identity), what the agent knows (topical), how to do things (procedural), and source material to reference (artifact). One conversation can update all five layers simultaneously.
An Evie Platform agent wakes up fresh every session. It has no built-in memory of yesterday's conversations, last week's decisions, or the person it's working for. Everything it knows comes from files it reads and databases it queries.
The memory system gives agents continuity across sessions. It's built on an activity log foundation and organized into five layers, each handling a different recall pattern with storage optimized for how that information gets accessed.
The Activity Log
Before the five memory layers, there's the foundation they all build on: the activity log. This is the raw signal layer. Slack messages, calendar events, meeting transcripts, email threads, git commits, voice memos -- everything flows through here first. The activity log is comprehensive and append-only. It's the ground truth.
Every source is opt-in. You choose what to connect. The agent works with whatever signals you provide; it will just be less informed without them.
The activity log lives directly in Postgres. The agent doesn't write this data; it ingests and queries it.
Five Layers
Episodic memory is the temporal layer -- what happened, when, and in what order. The activity log captures raw signals; episodes group related events into coherent stories. A morning Slack thread that continues over an afternoon call becomes a single episode. Daily session logs capture the raw stream, and a curated long-term file distills the important bits. The name comes from cognitive science: episodic memory is first-person, time-ordered, and naturally consolidates over time.
Identity memory is the reconciliation layer -- connecting the same person across different systems. The "Cedric Hurst" in Slack, the "cedric@spantree.net" in Google Calendar, the "divideby0" on GitHub, and "Karan's iPhone" on Zoom are all resolved to the same person automatically. Identity resolution happens in Postgres with confidence scoring, crosswalks, and manual overrides, following classic Master Data Management (MDM) patterns.
Topical memory is the domain knowledge layer -- accumulated expertise organized by subject. This covers both entities (people like Alice the CFO, organizations like Acme Corp, projects like the Q4 Migration) and abstract topics (Sarbanes-Oxley compliance, competitive landscape analysis, HIPAA requirements). Entities connect to identity records and link to each other. These are markdown files indexed by basic-memory into Supabase, with types aligned to Schema.org vocabulary and defined as Zod schemas for validation and programmatic use. Every new conversation enriches the knowledge graph rather than starting from scratch.
Procedural memory is the how-to layer -- self-updating playbooks that teach the agent new capabilities. This maps directly to the SKILL.md convention native to OpenClaw. Each skill combines progressive-disclosure markdown instructions with executable scripts. The agent can create or update its own skills as it learns new procedures. After closing three healthcare deals, it writes its own HIPAA checklist skill. Skill modifications are audited by independent agents for safety.
Artifact memory is the source material layer -- pure copies stored for retrieval and reference. Documents, YouTube transcripts, crawled website content, research reports. The key distinction: artifacts are stored for recall, not for side effects. When you say "find the proposal I sent last Tuesday," artifact memory retrieves the full text instantly. Updates happen through skills (edit in Google Drive), which produce new activity log entries.
How One Conversation Updates Five Layers
Consider a sales call where a CFO mentions her company's fiscal year ends in March and she hates morning meetings:
- Episodic: The call itself is captured as an episode
- Identity: Alice the CFO at Acme Corp is resolved as the same person as alice.chen@gmail.com
- Topical: "Hates morning meetings" gets filed under her person entity; fiscal year data goes to the org entry
- Procedural: How to update the CRM after a call is a learned procedure
- Artifact: The blog article she published about supply chain challenges is stored verbatim for retrieval
One conversation, five layers updated.
Memory Retrieval
With five layers accumulating over months, surfacing the right memories at the right time requires three mechanisms:
Hybrid search combines vector similarity (semantic matching via cosine distance on embeddings) with BM25 keyword matching (TF-IDF weighting for exact matches) and fuzzy search (trigram matching for typos and partial names). Results are merged using Reciprocal Rank Fusion (RRF), which sums reciprocal rank positions across methods so items that multiple methods agree on bubble to the top.
Memory vitality uses ACT-R (Adaptive Control of Thought -- Rational) to model how memory should decay. Memories don't fade linearly; they follow the power law of forgetting. Yesterday's meeting is vivid, last week's is accessible, three months ago has faded. But frequency fights decay: if you ask about a client every week, each access reinforces that context. A metabolic rate multiplier controls decay speed by memory type -- entity memory (0.1x) fades 10x slower than activity memory (3.0x), because a person's identity doesn't fade like yesterday's standup notes.
The Dream Cycle runs overnight consolidation. During the day, the agent does lightweight processing (real-time episode splitting). Overnight, seven phases run for about $0.40: ingesting raw signals, grouping episodes, consolidating observations, running gap analysis, firing proactive research, self-evaluating the day's performance, and generating action items for tomorrow. Think of it as REM sleep for the agent -- reinforcing strategically important memories before they drop below recall threshold.
Storage Architecture
All five layers plus the activity log converge on Supabase (Postgres) as the data backbone, though they use different access patterns.
| Layer | Primary Storage | Access Pattern |
|---|---|---|
| Activity Log | Postgres (TimescaleDB) | Time-range queries + full-text search |
| Episodic Memory | Markdown files | File reads + embedding search |
| Identity | Postgres | Lookup by identifier + fuzzy matching |
| Topical (Knowledge) | Markdown + Postgres (basic-memory) | Structured queries + semantic search |
| Procedural | SKILL.md files | File reads + skill registry |
| Artifact | Markdown + Postgres | Content-addressed retrieval |
Why Postgres?
The system uses up to four different query engines, and Postgres provides all of them as extensions on a single instance:
- pgvector for semantic similarity search over embeddings
- ParadeDB for BM25 full-text search with TF-IDF keyword matching
- TimescaleDB for time-series data powering vitality decay and activity log queries
- Standard relational queries for everything else
The alternative would be running separate Elasticsearch, Pinecone, and InfluxDB instances. Instead: one Postgres, one backup strategy, one connection pool.
Markdown files live in the workspace (workspaces/main/memory/ and workspaces/main/knowledge/). They're version-controlled, human-readable, and searchable via OpenClaw's built-in memory_search tool.
Postgres handles everything structured. basic-memory indexes knowledge files into Postgres for relational queries. Activity data from integrations goes directly into Postgres tables. Identity crosslinks and match candidates live in dedicated tables with foreign keys.
pgvector enables semantic search across all layers. Embeddings are generated for memory files, knowledge entities, and activity records, allowing the agent to find relevant context even when the exact words don't match.
Schema Alignment
Entity types in the knowledge and identity layers use fully-qualified type names to make provenance unambiguous:
schema.org/Person— a standard Schema.org type (portable, understood by LLMs natively)meetevie.dev/Project— a custom Evie Platform type (when no Schema.org type fits)
Schema.org types are open-world — you can freely add properties beyond what the spec defines. Most Evie Platform types use a standard Schema.org type with extension properties (e.g., schema.org/Report with mode, status, and providers fields for research notes). Custom meetevie.dev/* types are only created when no Schema.org type fits at all.
Property names use snake_case in YAML frontmatter and Postgres columns, mapped from Schema.org's camelCase equivalents at the serialization boundary (e.g., given_name ↔ Schema.org givenName).
Each type has a corresponding Zod schema for validation and programmatic use — see the Entity Types section for the full set.
Conventions
All markdown files in the memory system follow consistent formatting rules. See Markdown Format for the full specification, but the key principles are:
- Frontmatter stays lean — short scalars and block-style lists only. No long text.
- Long content goes in the body — descriptions, notes, and context as regular markdown.
- Observations and relations use basic-memory's knowledge graph syntax with a controlled vocabulary of categories and relation types.